Análise exploratória de casos de Zika notificado pelo SUS
Neste tutorial vamos explorar como começar a entender a descrição de casos do sistema de notificação de agravos do SUS, o SINAN. Estes dados são bastante ricos e a documentação sobre o significado de cada uma das variáveis pode ser encontrada aqui.
[1]:
from pysus.ftp.databases.sinan import SINAN
sinan = SINAN().load()
Primeiro vamos começar pelo carregamento dos dados a partir do site do InfoDengue. Como o dado está no formato parquet, nós vamos utilizar a biblioteca pandas para carregar os dados em um Dataframe.
[4]:
cols = [
'ID_AGRAVO', 'DT_NOTIFIC', 'SEM_NOT', 'NU_ANO', 'ID_MUNICIP',
'DT_SIN_PRI', 'SEM_PRI', 'NU_IDADE_N', 'CS_SEXO', 'CS_GESTANT',
'latitude', 'longitude',
'NM_DISEASE'
]
casos = sinan.download(sinan.get_files('ZIKA', 2016)).to_dataframe()
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4.14M/4.14M [00:00<00:00, 3.47GB/s]
Vejamos os nomes da variáveis
[5]:
casos.columns
[5]:
Index(['TP_NOT', 'ID_AGRAVO', 'CS_SUSPEIT', 'DT_NOTIFIC', 'SEM_NOT', 'NU_ANO',
'SG_UF_NOT', 'ID_MUNICIP', 'ID_REGIONA', 'DT_SIN_PRI', 'SEM_PRI',
'NU_IDADE_N', 'CS_SEXO', 'CS_GESTANT', 'CS_RACA', 'CS_ESCOL_N', 'SG_UF',
'ID_MN_RESI', 'ID_RG_RESI', 'ID_PAIS', 'NDUPLIC_N', 'IN_VINCULA',
'DT_INVEST', 'ID_OCUPA_N', 'CLASSI_FIN', 'CRITERIO', 'TPAUTOCTO',
'COUFINF', 'COPAISINF', 'COMUNINF', 'DOENCA_TRA', 'EVOLUCAO',
'DT_OBITO', 'DT_ENCERRA', 'CS_FLXRET', 'FLXRECEBI', 'TP_SISTEMA',
'TPUNINOT'],
dtype='object')
[6]:
casos = casos[casos.ID_AGRAVO=='A928']
casos.head()
[6]:
| TP_NOT | ID_AGRAVO | CS_SUSPEIT | DT_NOTIFIC | SEM_NOT | NU_ANO | SG_UF_NOT | ID_MUNICIP | ID_REGIONA | DT_SIN_PRI | ... | COPAISINF | COMUNINF | DOENCA_TRA | EVOLUCAO | DT_OBITO | DT_ENCERRA | CS_FLXRET | FLXRECEBI | TP_SISTEMA | TPUNINOT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | A928 | 2016-01-26 | 201604 | 2016 | 33 | 330490 | 2016-01-19 | ... | 0 | 1 | 20160331 | 0 | 2 | 1 | ||||||
| 1 | 2 | A928 | 2016-01-26 | 201604 | 2016 | 33 | 330490 | 2016-01-20 | ... | 0 | 20160331 | 0 | 2 | 1 | |||||||
| 2 | 2 | A928 | 2016-01-26 | 201604 | 2016 | 33 | 330490 | 2016-01-18 | ... | 0 | 9 | 1 | 20160326 | 0 | 2 | 1 | |||||
| 3 | 2 | A928 | 2016-01-26 | 201604 | 2016 | 33 | 330490 | 2016-01-19 | ... | 0 | 9 | 1 | 20160331 | 0 | 2 | 1 | |||||
| 4 | 2 | A928 | 2016-01-26 | 201604 | 2016 | 33 | 330490 | 2016-01-19 | ... | 0 | 9 | 1 | 20160331 | 0 | 2 | 1 |
5 rows × 38 columns
Estes dados correspondem a todos os casos de Zika notificados ao SUS durante um período. Neste caso de 2015 a 2016. Para podermos tratar adequadamente estes dados para fins de visualização ou análise precisamos corrigir os tipos das colunas. Por exemplo vamos converter as datas.
[5]:
import pandas as pd
casos['DT_INDEX'] = pd.to_datetime(casos.DT_NOTIFIC)
Para poder organizar os dados temporalmente, é útil indexar a tabela por alguma variável temporal. Vamos usar a data de notifiacão de cada caso como índice
[6]:
casos = casos.set_index('DT_INDEX')
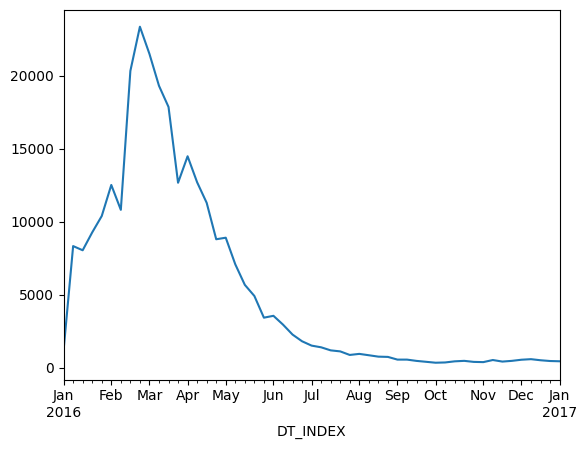
Agora podemos plotar o número de casos por semana de dengue na cidade do Rio de Janeiro.
[7]:
casos.ID_AGRAVO.resample('1W').count().plot()
[7]:
<Axes: xlabel='DT_INDEX'>
Suponhamos agora que desejamos visualizar em um mapa os casos que ocorreram, por exemplo entre janeiro e agosto de 2016.